The term Machine Learning was coined by Arthur Samuel in 1959, an American pioneer in the field of computer gaming and artificial intelligence, and stated that “it gives computers the ability to learn without being explicitly programmed”.
Machine learning is a subfield of artificial intelligence (AI). The goal of machine learning generally is to understand the structure of data and fit that data into models that can be understood and utilized by people for automation and decision support systems.
Machine learning is a field of transforming information into knowledge. Machine learning techniques are used to automatically find the valuable underlying patterns within complex data which would be almost impossible to extract by the humans.
Need and Applications of Machine Learning
Machine learning is an emerging field as there is rapid increment in volumes and variety of data, the access and affordability of computational power, and the availability of high speed Internet.
The Concept of Machine Learning can be applied to any organization/domain to in order to cut costs, mitigate risks, and improve overall quality of life including recommending products/services, detecting cybersecurity breaches, and enabling self-driving cars. With greater access to data and computation power, machine learning is becoming more ubiquitous every day and will soon be integrated into many facets of human life.
In the earlier days, to help user with the decision from machine, the systems used hardcoded rules of if and else construct. To take an example of sentiment analysis, to classify the text as positive or negative, list of positive and negative words can be constructed and then the rules can be applied. However, this is not the feasible solution. So, moving from Bag of words, n-grams, skip-grams, word2vec, doc2vec and the transformers model, now the sentiment analysis has been a common task due to the advancements in machine learning and vector representation.
Some of the application of machine learning includes:
- Fraud Detection Systems
- Customer Churn Prediction
- Association Minining
- Handwritten Optical Character Recognition
- Regression Analysis
- Recommendation System
- Chatbots
- Machine Translation
Traditional Programming Vs. Machine Learning
In traditional Programming, data and program is fed to the computer to produce the output. Traditional programming is a manual process where a programmer creates the program. But without anyone programming the logic, one has to manually formulate or code rules.
Data and output is fed to the computer to create a program which is then used in traditional programming. In Machine Learning the algorithms automatically formulate the rules from the data, which is very powerful in many business and automation aspects.
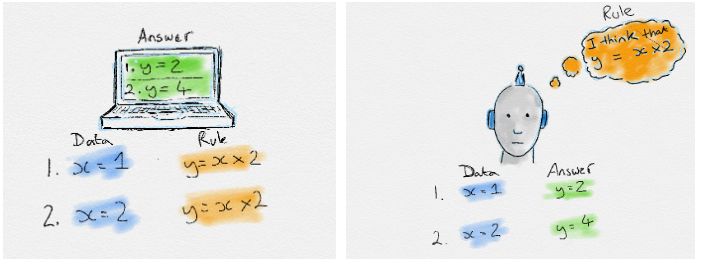
Types of Machine Learning Systems
Supervised Learning
In supervised learning, the system is provided with data that are labeled with their desired outputs. The purpose of this method is for the algorithm to be able to “learn” by comparing its actual output with the “taught” outputs to find errors, and modify the model accordingly. Supervised learning therefore uses patterns to predict label values on additional unlabeled data.
In supervised learning, you will have input X with labels y. Any algorithm under this approach is used to learn the mapping function that maps the input X to output y. Hence, the ultimate target is to approximate the function such that the new test inputs are mapped correctly.
Supervised Learning can be further divided into two categories:
- Classification
- Regression
Classification
Classification is a process of categorizing a given set of data into particular group known as class or labels. The dataset needed for the classification task includes features and labels. Some of the classification tasks includes the following:
- Classifying the images as cat vs dog.
- Classifying the emails as spam or ham.
- Classifying Movie Genere.
- Classifying the tumor types in medical imaging.
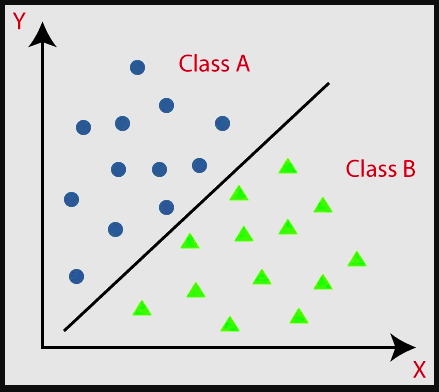
Some of the popular classification algorithms are as follows:
- Logistic Regression
- K-Nearest Neighbors
- Decision Trees
- Support Vector Machine
Regression
Regression is the kind of Supervised Learning that learns from the Labelled Datasets and is then able to predict a continuous-valued output for the new data given to the algorithm. It is used whenever the output required is a number such as money or height etc. Some of the regression tasks are as follows:
- Sales Forecasting in Super Markets
- House Price Prediction
- Prediction of person’s annual income
- Crop yield Prediction
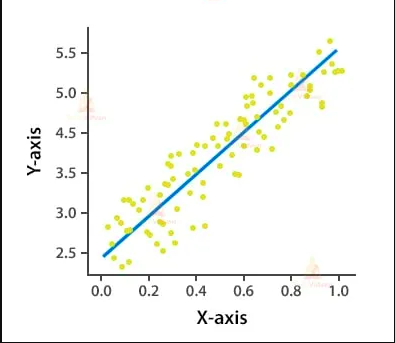
The future values are predicted from the past data.
Some of the popular regression algorithms are as follows:
- Linear Regression
- Random Forest Regressor
- Ridge Regression
- Lasso Regression
- Polynomial Regression
Unsupervised Learning
In unsupervised learning, the data used has no labels. Algorithm here learns to extract the patterns from the data. The algorithm is trained with unlabelled data to extract the knowledge from them.
Some of the popular Unsupervised learning algorithms are as follows:
- Clustering
- Dimensionality Reduction
Clustering
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar/homogeneous to other data points in the same group and dissimilar/hetereogeneous to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them.
Clustering is widely used approach for the tasks like:
- Market Segmentation
- Statistical data analysis
- Social network analysis
- Image segmentation
- Anomaly detection
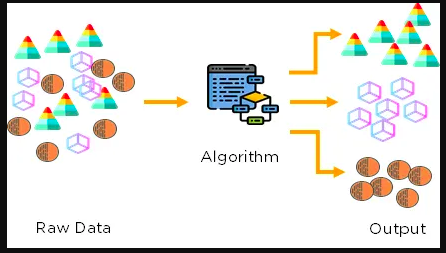
Some of the popular clustering algorithms are as follows:
- KMEANS
- Density-Based Spatial Clustering of Applications with Noise(DBSCAN).
- Agglomerative Hierarchical algorithm.
Dimensionality Reduction
As data is key to machine learning algorithms, the features present in the data describes the story behind the data. The number of input features, variables, or columns present in a given dataset is known as dimensionality. All the features in the dataset may not be required for the algorithm and the features might be redundant as well. This creates an obstacle and difficulty to visualize the data. In such scenario, dimensionality reduction becomes much more effective.
Some of the popular dimensionality reduction techniques includes:
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
Reinforcement Learning
Reinforcement Learning is learning what to do and how to map situations to actions. The end result is to maximize the numerical reward signal. The learner is not told which action to take, but instead must discover which action will yield the maximum reward.
It is a type of machine learning technique that can enable an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences.
RL solves a specific type of problem where decision making is sequential, and the goal is long-term, such as game-playing, robotics, trading, etc.

The major components of RL includes the following:
- Agent: An entity that can perceive/explore the environment and act upon it.
- Environment: A situation in which an agent is present or surrounded by. In RL, we assume the stochastic environment, which means it is random in nature.
- Action: Actions are the moves taken by an agent within the environment.
- State: State is a situation returned by the environment after each action taken by the agent.
- Reward: A feedback returned to the agent from the environment to evaluate the action of the agent.