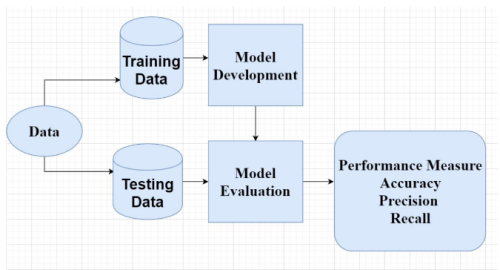
The decision tree is the most popular and powerful supervised machine learning algorithm which is used to build classification models. The target result is already known in supervised learning.
It builds classification models in the form of a tree-like structure. The structure of the decision tree represents the root node, branches and leaf nodes, where an internal node represents attributes, the branch represents a decision rule, and each leaf node represents the outcome. The partition has been done on the basis of the attribute value.
Decision Tree Model Structure
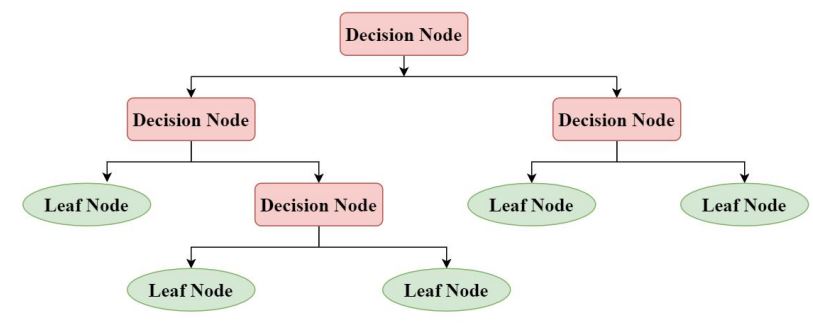
Decision trees can be work in both categorical and numerical data. The categorical data represent gender, marital status, etc. while the numerical data represent age, temperature, etc.
Decision Tree Algorithm Working Process
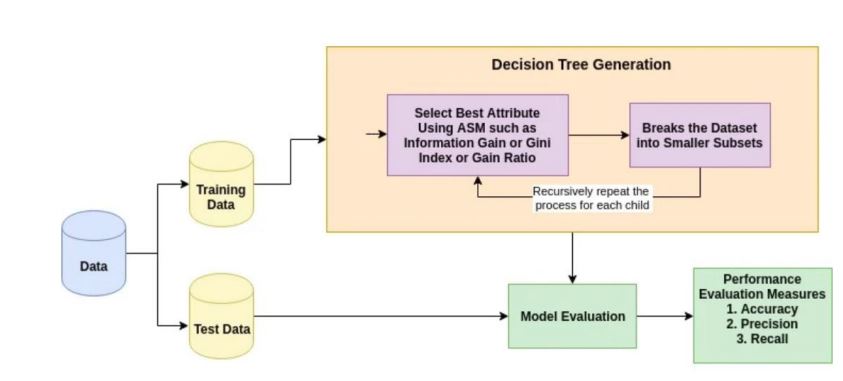
- Select the best attribute using Attribute Selection Measures (ASM) to split the records.
- Make that attribute a decision node and breaks the dataset into smaller subsets.
- Start tree building by repeating this process recursively for each.
Information Gain
Entropy measures the impurity of the input set. It controls how a Decision Tree decides to split the data. It actually effects how a Decision Tree draws its boundaries. Information gain is indeed the decrease in entropy when a dataset is split based on a particular attribute. Information gain computes the difference between entropy before split and average entropy after split of the dataset based on given attribute values.
The ID3 (Iterative Dichotomiser 3) algorithm is a popular decision tree algorithm that uses the concept of information gain to make decisions on attribute selection. Information gain is a measure of the reduction in entropy (or increase in information) obtained by splitting the data based on a particular attribute.

Where,
Info (D) is the average amount of information needed to identify the class label of a tuple in D.
|Dj|/|D| acts as the weight of the jth partition.
InfoA(D) is the expected information needed to classify a tuple from D based on the partitioning by A.
Building a decision tree classifier using the scikit-learn library in Python
Here’s a simple example of building a decision tree classifier using the scikit-learn library in Python:
- Import the required libraries
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
2. Load the dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
3. Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)X refers to the input data.
y refers to the target variable or the output we want to predict.
test_size=0.2 indicates that we want to allocate 20% of the data for testing, while the remaining 80% will be used for training the model.
random_state=42 It shows that the same random split will be generated every time the code is executed.
4. Create the decision tree classifier
clf = DecisionTreeClassifier()5. Train the classifier on the training data
clf.fit(X_train, y_train)6. Make predictions on the testing data
y_pred = clf.predict(X_test)
7. Calculate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
In this article, we provided an introduction to decision tree algorithms and demonstrated a simple implementation in Python using the scikit-learn library. Decision trees are versatile and powerful models that can be applied to various domains. By understanding and implementing decision trees, you can enhance your machine learning skills and make informed decisions based on data analysis.