A Convolutional Neural Network (CNN) is a type of deep neural network that is commonly used in computer vision tasks such as image classification, object detection, and segmentation. CNNs are inspired by the way the human brain processes visual information and are designed to automatically learn hierarchical representations of features from raw input data.

The input to a convolutional layer is a ‘m x m x r’ image where m is the height and width of the image and r is the number of channels, e.g. an RGB image has ‘r=3’. The convolutional layer will have k filters (or kernels) of size ‘n x n x q’ where n is smaller than the dimension of the image and q can either be the same as the number of channels ‘r’ or smaller and may vary for each kernel. The size of the filters gives rise to the locally connected structure which are each convolved with the image to produce k feature maps of size ‘m−n+1’. Each map is then subsampled typically with mean or max pooling over ‘p x p’ contiguous regions where p ranges between 2 for small images and is usually not more than 5 for larger inputs. Either before or after the subsampling layer activation functions like Sigmoid, ReLU, tanh, etc. are applied to each feature map.
The general architecture of CNN is presented below:
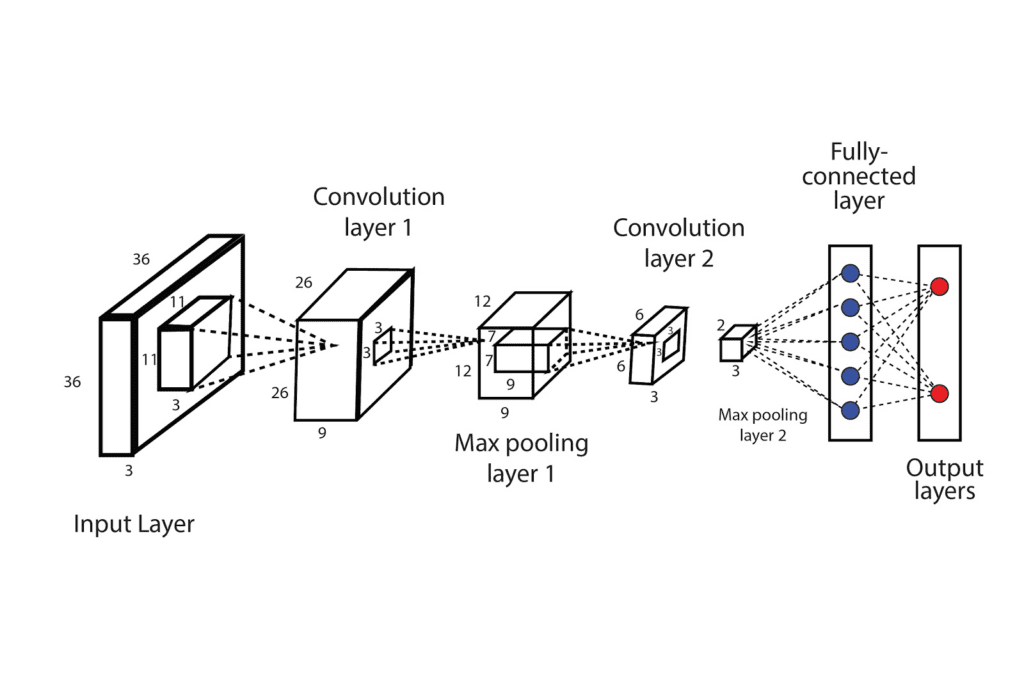
The specific layers used in a CNN architecture can vary depending on the task and the complexity of the input data. Different architectures, such as AlexNet, VGG, and ResNet, use different combinations of these layers to achieve state-of-the-art performance on various computer vision tasks. The first architecture of CNN is the LeNet, demonstrated by Yann LeCun for recognizing handwritten digits of a popular dataset known as MNIST.
Layers in Convolutional Neural Network
CNNs consist of various layers that process the input image in a specific way. These layers include the input layer, convolutional layer, activation function, pooling layer, fully connected layer, dropout layer, and output layer. Each layer serves a specific purpose in extracting useful features from the input data and producing the final output predictions. The specific layers used in a CNN architecture can vary depending on the task and the complexity of the input data. Different CNN architectures use different combinations of these layers to achieve state-of-the-art performance on various computer vision tasks.
Input Layer
The input layer of a CNN is where the raw input data is fed into the network. In image recognition tasks, the input is typically a 3D tensor of shape (height, width, channels), where height and width are the dimensions of the input image, and channels represent the color channels (e.g., red, green, blue).
Convolutional Layer
Convolutional layers apply a set of filters (also known as kernels or weights) to the input image to extract features. Each filter is slid over the input image and produces a feature map, which represents the output of that filter for each location in the image. The output of multiple filters is stacked to form a 3D tensor, which is the output of the convolutional layer.
It computes the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. The convolutional layer is used to recognize the spatial patterns in image, such as lines and parts of objects. This is the layer which contains most of the user-defined parameters of the CNN architecture such as:
- Number of Kernels
- Size of Kernels (includes only height and width, the dimension is specified by the input image)
- Strides
- Padding
- Activation Functions
The output of the convolutional layer is passed immediately through activation functions.
If we apply a convolution operation on a grayscale input image of size 32*32*1, kernel size of 5*5 and output channel 6, the output dimension of the first convolutional layer is given as:
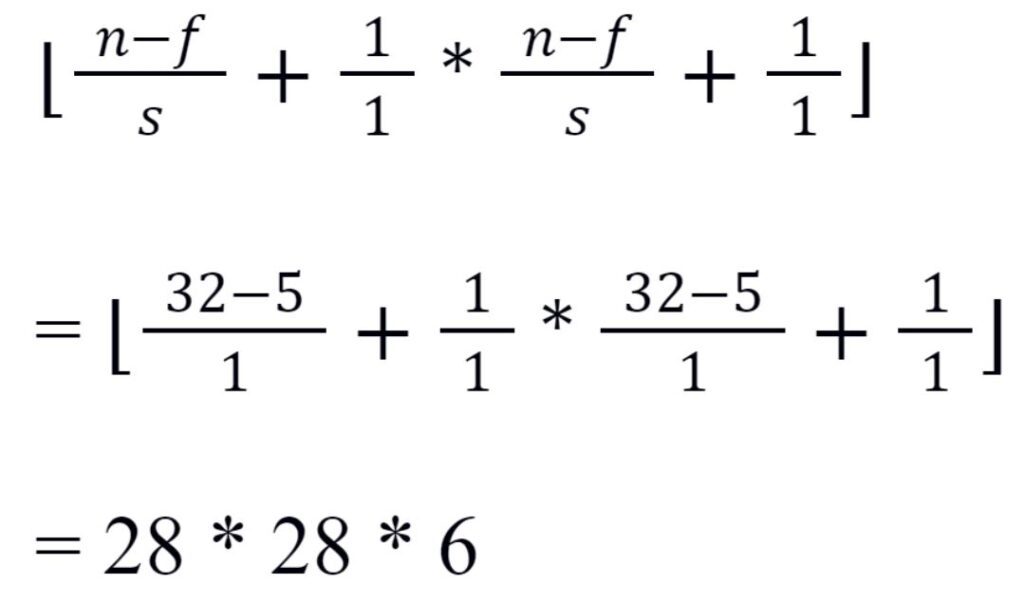
Activation Function
After the convolutional layer, an activation function such as ReLU is typically applied element-wise to introduce non-linearity into the network.
The ReLU activation function provides a simple non-linear transformation. The performance of this function is good on predictive models. The mathematical concept behind this is also simple and for any given input x, the function is defined as the maximum of 0 and the provided input.
ReLU(x) = max(0, x)
This shows that ReLU activation function retains only the positive inputs and discards all the negative inputs which decreases the complexity as the negative weighted neurons are deactivated. ReLU allows the network to converge quickly. There are varieties of ReLU activation such as Leaky ReLU, Parametric ReLU, however the system implements the very basic one discussed above.

Pooling Layer
Pooling layers are used to downsample the feature maps and reduce their spatial dimensions. The most common type of pooling is max pooling, where the maximum value in each pooling region is selected as the output. This helps to reduce the number of parameters and improve the efficiency of the network. Pooling layer involves the process of decreasing the number of parameters to be calculated by the network in each layer. Thus, pooling layers helps to decrease the computational complexity of the network. Pooling layer works on the principle of sliding window. There are two common pooling layers as discussed below:
Max-pooling Layer
The max pooling layer, as the name suggests, stores maximum value obtained in the window when it slides over the window frame of size (f,f).
Average-pooling Layer
The average pooling layer, as the name suggests, stores the average value obtained in the window when it slides over the window frame of size (f,f).

After applying a 2*2 max pooling layer with a stride of 2 on the output feature map of the first convolutional layer, which has a size of 28*28*6, we can obtain the resulting output feature map dimensions of the pooling layer as:

The output of the pooling layer is then passed to the second convolutional layer and the process is repeated.
Fully Connected Layers
Fully connected layers are used to classify the input image based on the learned features. Each neuron in the fully connected layer is connected to every neuron in the previous layer, and the output of the layer is passed through a softmax activation function to produce a probability distribution over the possible classes.
Dropout Layers
Dropout layers are used to prevent overfitting by randomly dropping out some neurons during training. This helps to reduce the dependence on individual neurons and improve the generalization ability of the network.
In convolutional neural networks (CNNs), dropout can be applied to the fully connected layers after the convolutional layers. It can also be applied to the convolutional layers themselves, although this is less common. When applying dropout to convolutional layers, it is typically done by randomly setting a percentage of the feature map values to zero during each training iteration.
It is important to note that dropout should only be applied during training and not during testing or inference, as all neurons should be active during testing to obtain accurate predictions.
Output Layer
The output layer of a CNN is the final layer of the network, which produces the output predictions. In classification tasks, the output layer typically has one neuron per class, and the predicted class is the one with the highest output value.