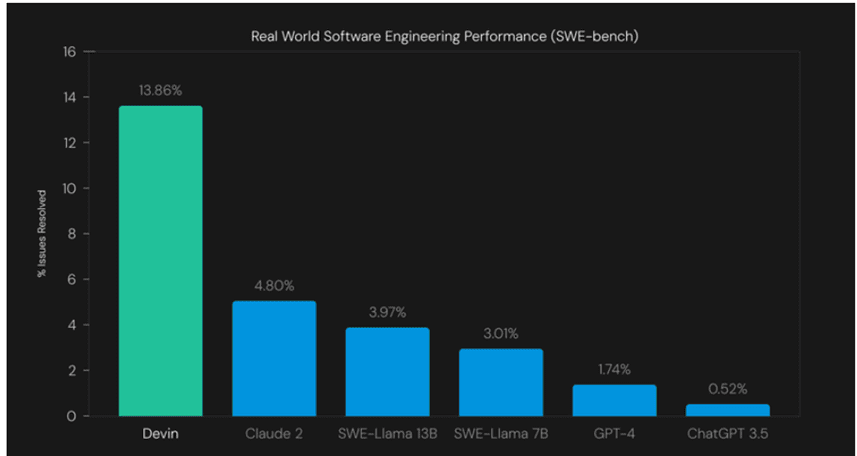
Recurrent Neural Networks – Background
Recurrent Neural Networks (RNNs) have been widely used for sequence modeling problems in natural language processing (NLP) due to their ability to process sequential data one element at a time. In particular, Long Short-Term Memory (LSTM) and Gated Recurrent Neural Network (GRU) variants of RNNs have been shown to be effective in modeling long-term dependencies in sequential data.
However, one major drawback of RNNs is their sequential nature, which makes them computationally expensive and time-consuming to train, particularly for long sequences. Additionally, the processing order of the sequence is fixed, which can limit the ability of the model to capture the global context of the sequence.
To address these issues, transformers were introduced as an alternative approach to sequence modeling in NLP. Unlike RNNs, transformers do not process the input data in order, but rather use an attention mechanism that allows the model to selectively focus on different parts of the input sequence based on their relevance to the task at hand. This attention mechanism provides the model with a way to capture global context and long-range dependencies in the sequence, making it particularly effective for language modeling and other NLP tasks.
Furthermore, the attention mechanism in transformers allows for greater parallelization during training, making them more computationally efficient than RNNs. This has led to transformers achieving state-of-the-art performance on a range of NLP tasks, including language modeling, machine translation, and sentiment analysis.
Transformers – Introduction
The transformer is a type of neural network architecture that leverages the power of attention mechanisms to gain a deeper understanding of words in an input sequence. The attention mechanism allows the model to selectively focus on important elements of the sequence, making it more efficient and accurate than traditional models that process data in a sequential manner.
At the heart of the transformer model is the self-attention mechanism, which allows the model to consider the relationship between all the words in the input sequence simultaneously. This means that the model can identify important patterns and dependencies in the data, regardless of the order in which the words appear.
In addition to self-attention, the transformer model also includes multi-head attention, which further enhances its ability to capture complex patterns in the data. This is achieved by allowing the model to attend to different parts of the sequence with multiple sets of attention weights, which are then combined to produce a more robust and accurate representation of the input sequence.
By using attention mechanisms, transformers are able to learn and recognize patterns in data much faster than other neural network models, resulting in more accurate predictions and a shorter training time. This has made transformers an important tool for a variety of applications in natural language processing, including language translation, sentiment analysis, and text generation.
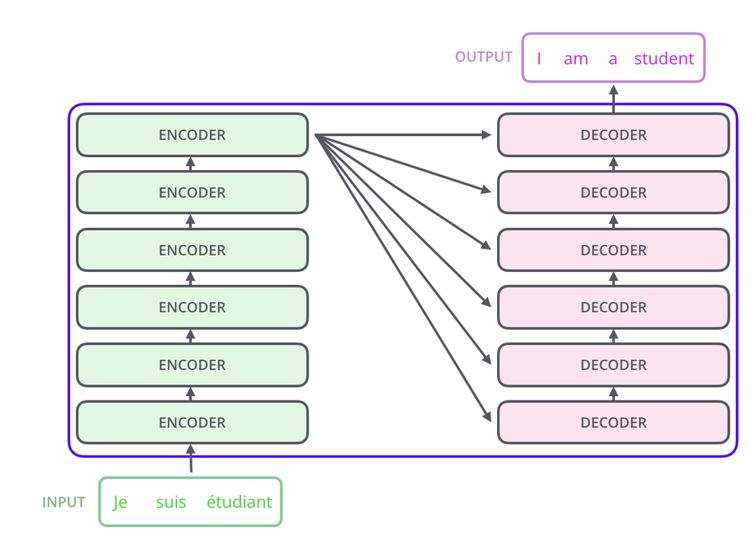
The transformer model is composed of a series of encoder and decoder layers that are linked together. The input data passes through the encoder layers in sequence before being forwarded to the decoder layer for additional processing.
Each encoder layer contains two sub-layers: a self-attention layer and a feedforward neural network. The self-attention layer allows the model to selectively focus on different parts of the input sequence, while the feedforward neural network applies a non-linear transformation to the output of the self-attention layer.
The decoder layer also includes a self-attention layer, as well as an encoder-decoder attention layer, which allows the model to attend to relevant parts of the input sequence as it generates output.
Transformers – Popular types of Architecture
There are several popular transformer architectures that have been widely adopted for various NLP tasks. Here are some of the most popular ones:
- BERT (Bidirectional Encoder Representations from Transformers): This is a pre-trained transformer model developed by Google that uses a bidirectional approach to capture context from the entire input sequence. It has achieved state-of-the-art results on a wide range of NLP tasks, including sentiment analysis, text classification, and named entity recognition.
Paper Link: [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
- GPT (Generative Pre-trained Transformer): This is a transformer-based language model developed by OpenAI that uses an autoregressive approach to generate natural language text. It has achieved impressive results on tasks such as language modeling, machine translation, and text generation.
- RoBERTa (Robustly Optimized BERT Pre-training Approach): This is another pre-trained transformer model developed by Facebook AI that builds on the success of BERT by using additional pre-training techniques to improve its performance on a range of NLP tasks.
Paper Link: [1907.11692] RoBERTa: A Robustly Optimized BERT Pretraining Approach (arxiv.org) - T5 (Text-to-Text Transfer Transformer): This is a transformer-based model developed by Google that uses a unified architecture for a range of NLP tasks, including question answering, language translation, and text summarization. It achieved state-of-the-art results on several benchmarks.
Paper Link: [1910.10683] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (arxiv.org) - ALBERT (A Lite BERT): This is a lightweight version of the BERT model that uses parameter sharing and cross-layer parameter sharing to reduce the number of parameters and improve training efficiency without sacrificing accuracy.
Paper Link: [1909.11942] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (arxiv.org) - XLNet: This is a transformer-based language model developed by Carnegie Mellon University and Google that uses a permutation-based approach to model all possible orders of the input sequence. It achieved state-of-the-art results on a wide range of NLP tasks.
Paper Link: [1906.08237] XLNet: Generalized Autoregressive Pretraining for Language Understanding (arxiv.org) - ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately): This is a transformer-based model that uses a novel pre-training approach to improve efficiency and reduce the amount of labeled data required for training. It has achieved state-of-the-art results on several benchmarks.
Paper Link: [2003.10555] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (arxiv.org)
Transformers – More Resources
If you want to learn more about transformers and experiment with various transformer models, you should visit huggingface.co. This website provides a wealth of information and resources on transformer models and offers easy-to-use tools for testing and deploying these models in your own projects. Whether you’re a researcher, developer, or just someone interested in NLP, huggingface.co is the go-to destination for all things transformers.