Machine learning is transforming industries, driving decision-making, and powering the most advanced artificial intelligence systems in the world. At its core, machine learning (ML) is about using data to build models that can make predictions or uncover hidden patterns without being explicitly programmed.
This guide dives deep into the most essential machine learning algorithms that every data scientist, data analyst, or machine learning engineer should master—grouped into Supervised, Unsupervised, Semi-Supervised, and Reinforcement Learning categories.
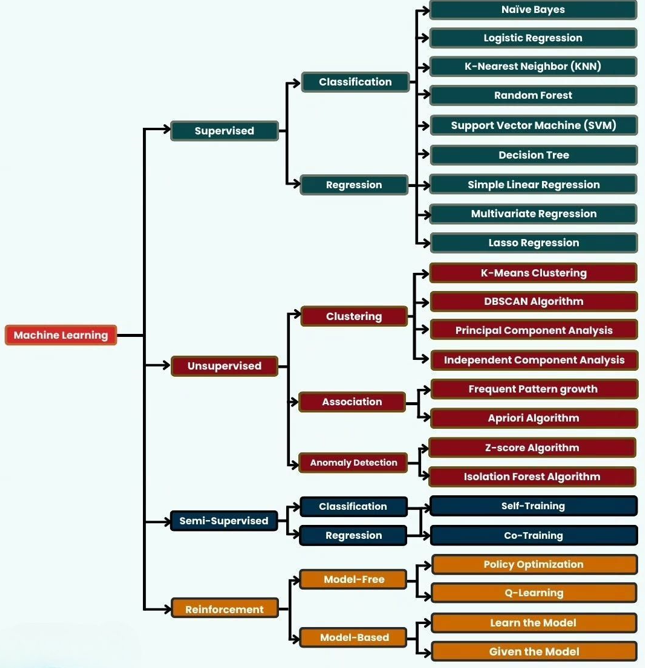
Supervised Learning Algorithms
Supervised learning uses labeled data, meaning the model is trained on input-output pairs. It’s ideal for prediction tasks where historical data is available.
Classification Algorithms
Classification problems involve categorical outputs, like spam detection or image recognition.
Naïve Bayes
- Based on Bayes’ Theorem with strong independence assumptions.
- Works well with text classification, like spam filtering.
- Fast and scalable with high dimensional data.
Logistic Regression
- A statistical model that predicts binary outcomes.
- Uses a logistic (sigmoid) function to map predictions between 0 and 1.
- Extensible to multiclass classification using softmax (multinomial logistic regression).
K-Nearest Neighbor (KNN)
- Lazy learning algorithm; no training phase.
- Classifies a point based on the majority label among its k nearest neighbors.
- Sensitive to irrelevant features and feature scaling.
Random Forest
- Ensemble of decision trees, trained on different parts of the dataset using bagging.
- Robust to overfitting, handles missing data well, and ranks feature importance.
- Suitable for both classification and regression.
Support Vector Machine (SVM)
- Finds the hyperplane that maximizes the margin between classes.
- Effective in high-dimensional spaces.
- Kernel trick allows for non-linear classification.
Decision Tree
- Simple tree structure where each node represents a decision rule.
- Easy to interpret, but prone to overfitting without pruning.
Regression Algorithms
Regression problems have continuous numeric outputs, such as predicting house prices or stock prices.
Simple Linear Regression
- Models relationship between a single feature and a target variable.
- Line of best fit: y=mx+by = mx + by=mx+b
Multivariate Regression
- Extends linear regression to multiple independent variables.
- Useful when many features contribute to the output.
Lasso Regression
- Adds L1 regularization to penalize large coefficients.
- Encourages sparsity (automatically selects features).
- Effective for high-dimensional data.
Unsupervised Learning Algorithms
Unsupervised learning works with unlabeled data and seeks to uncover hidden patterns or structure.
Clustering Algorithms
These algorithms group data into clusters based on similarity.
K-Means Clustering
- Partitions data into k clusters by minimizing within-cluster variance.
- Requires predefining number of clusters.
- Efficient for large datasets but sensitive to outliers.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Identifies dense regions as clusters and labels sparse regions as noise.
- Doesn’t require number of clusters in advance.
- Ideal for non-globular clusters and noisy datasets.
Principal Component Analysis (PCA)
- Dimensionality reduction technique using eigenvectors and eigenvalues.
- Projects data to a lower-dimensional space while retaining maximum variance.
- Useful for visualization and noise reduction.
Independent Component Analysis (ICA)
- Similar to PCA but focuses on statistical independence.
- Widely used in signal processing (e.g., separating mixed audio signals).
Association Algorithms
Used to identify interesting relationships and patterns in transactional data.
Frequent Pattern Growth (FP-Growth)
- Efficiently finds frequent itemsets without candidate generation.
- Faster than Apriori for large datasets.
Apriori Algorithm
- Classic algorithm to find frequent itemsets.
- Uses support and confidence metrics for rule generation.
- Prone to computational overhead with large datasets.
Anomaly Detection Algorithms
Identify data points that deviate from the norm.
Z-Score Algorithm
- Measures how many standard deviations a data point is from the mean.
- Assumes data is normally distributed.
Isolation Forest
- Randomly selects features and splits data.
- Anomalies are isolated quickly, thus requiring fewer splits.
- Scalable and effective for high-dimensional datasets.
Semi-Supervised Learning Algorithms
Semi-supervised learning is a hybrid approach that uses a small amount of labeled data and a large amount of unlabeled data. It balances cost-effectiveness with performance.
Self-Training
- The model is initially trained on labeled data.
- It then labels the most confident predictions from unlabeled data and retrains iteratively.
Co-Training
- Two models are trained on different views of the data.
- They label each other’s data in iterations to improve performance.
Reinforcement Learning (RL)
Reinforcement learning is about learning by interacting with the environment. The model learns a policy that maximizes cumulative reward over time.
Model-Free Methods
These methods do not assume any model of the environment.
Policy Optimization
- Directly optimizes the policy function using methods like REINFORCE or Proximal Policy Optimization (PPO).
- Effective in continuous action spaces.
Q-Learning
- Value-based method that learns the expected utility of actions in given states.
- Popular variant: Deep Q-Learning (DQN) using neural networks.
Model-Based Methods
These methods learn or use a model of the environment.
Learn the Model
- The agent tries to learn the dynamics of the environment (state transitions and rewards).
- Useful in planning future actions efficiently.
Given the Model
- Assumes the environment model is known.
- Algorithms like Value Iteration and Policy Iteration can be applied.
Conclusion: Why Mastering These Algorithms Matters
Mastering these algorithms isn’t just about memorizing formulas. It’s about:
- Knowing when to use what.
- Understanding the trade-offs between accuracy, speed, and interpretability.
- Adapting algorithms to real-world data challenges like missing values, high dimensionality, or noise.
Whether you’re building a fraud detection engine, forecasting stock trends, or optimizing a robot’s path, these machine learning algorithms form the backbone of modern AI solutions.
Tips for Data Scientists
- Always explore the data before jumping into modeling.
- Use cross-validation to evaluate model performance reliably.
- Scale your features for distance-based algorithms like KNN and SVM.
- Regularly monitor overfitting vs underfitting and apply regularization accordingly.