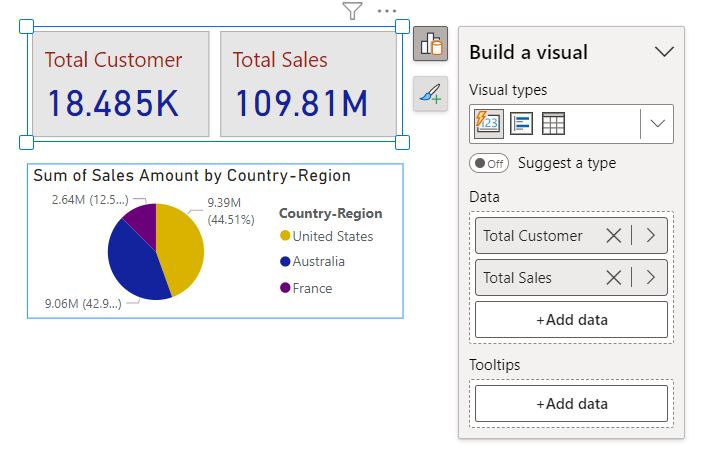
Pandas is a Python library for data manipulation and analysis. It provides data structures and operations for manipulating numerical tables and time series data. The most commonly used data structures in Pandas are the Series (1-dimensional) and DataFrame (2-dimensional) objects. Pandas makes it easy to work with large datasets and perform operations like filtering, grouping, and joining tables. It is widely used in data science and has strong integration with other popular libraries such as NumPy and Matplotlib.
import Pandas library
Import pandas as pdData Importing Packages:
- pd.read_csv()
- pd.read_table()
- pd.read_excel()
- pd.read_sql()
- pd.read_jason()
- pd.read_html()
- pd.dataframe()
- pd.concat()
- pd.series()
- pd.date_range()
Data Cleaning Packages:
- pd.fillna()
- pd.dropna()
- pd.sort_values()
- pd.apply()
- pd.groupby()
- pd.append()
- pd.join()
- pd.rename()
- pd.set_index()
Data Statistic Packages:
- pd.head()
- pd.tail()
- pd.describe()
- pd.info()
- pd.mean()
- pd.median()
- pd.count()
- pd.std()
- pd.max()
- pd.min()
Please follow and like us: